Splitting (and Chunking)
Let's say you want to summarize a long document. You could divide the document into an array of smaller pieces of text (chunking), and then iterate over each piece of text to summarize it (splitting), before summarizing the summaries.
For this tutorial, we will use the graph in the "6. Splitting" folder. Download the documentation-tutorial.rivet-project here and open it in Rivet to follow along!
Chunking
The first step of dividing a document into an array is called "chunking" in Rivet. The Chunk Node takes a string, and divides it into chunks of a certain token size.
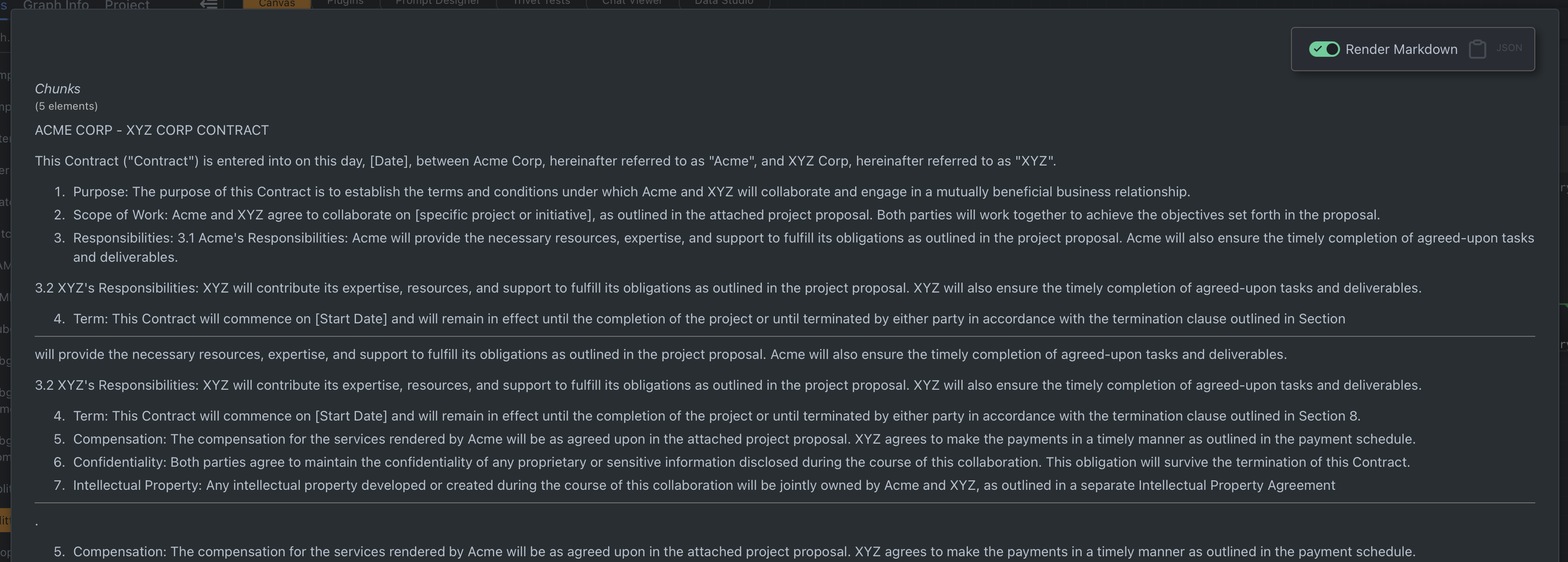
Try running the tutorial example, and notice that the Chunk Node output has N elements. Now, try increasing overlap to 50%. The output likely now has more than N elements. Overlap makes each chunk share some text from the beginning and end of the next and previous chunks. This is helpful to account for sentences or ideas that might otherwise be split across chunks.
In the screenshot below, you can see that "3.2 XYZ's Responsibilities" appears in both chunk 0 and 1, while "5. Compensation" appears in both chunk 1 and 2.
Splitting
The next step is iterating over each piece of text in the array. In Rivet, nodes have a "split mode," which allows them to iterate over arrays. When split mode is on, the split icon (circled below in red) will show next to the node title.
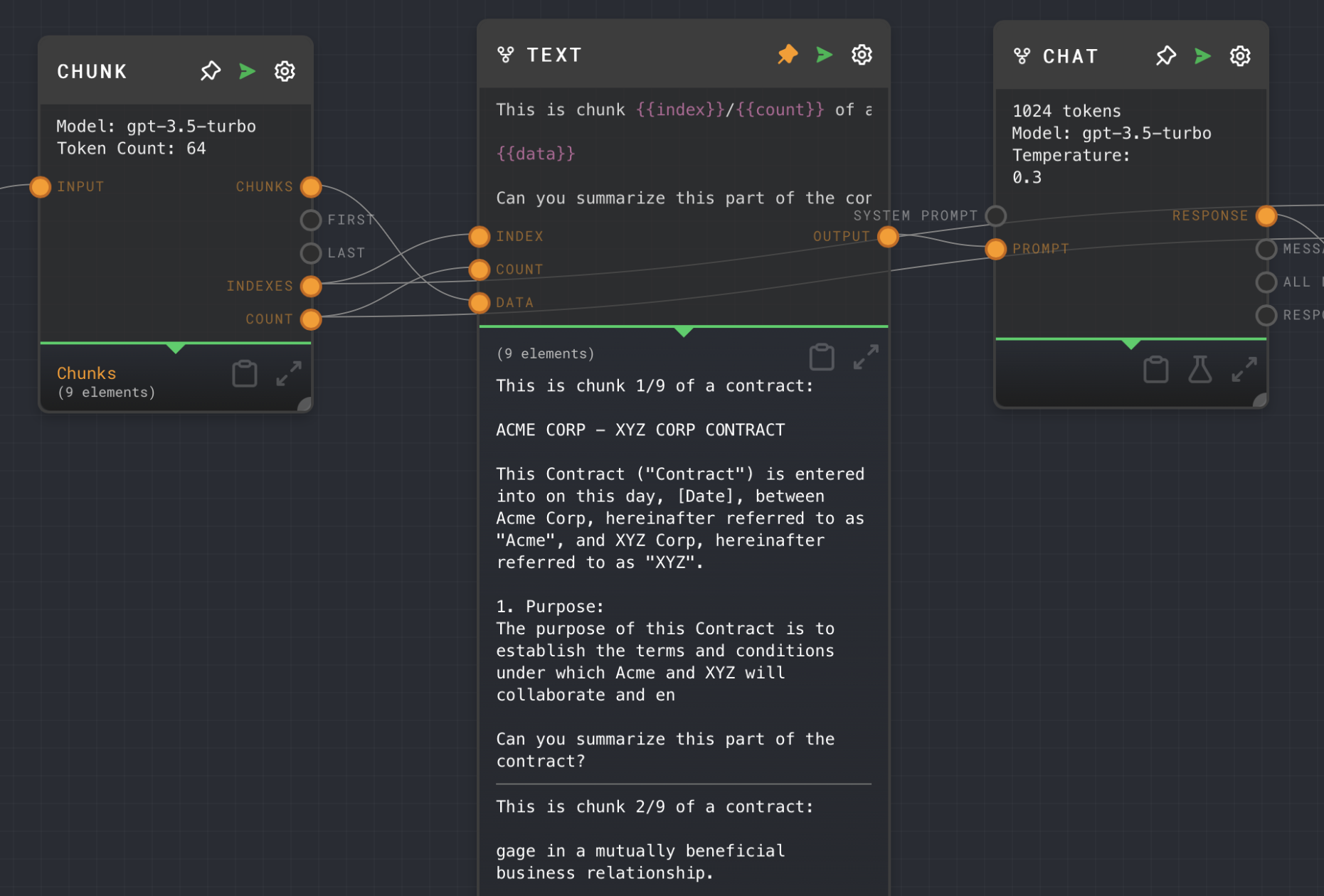
Try running the tutorial example, and notice that the Text Node outputs an array, with the text chunks inserted into the template.
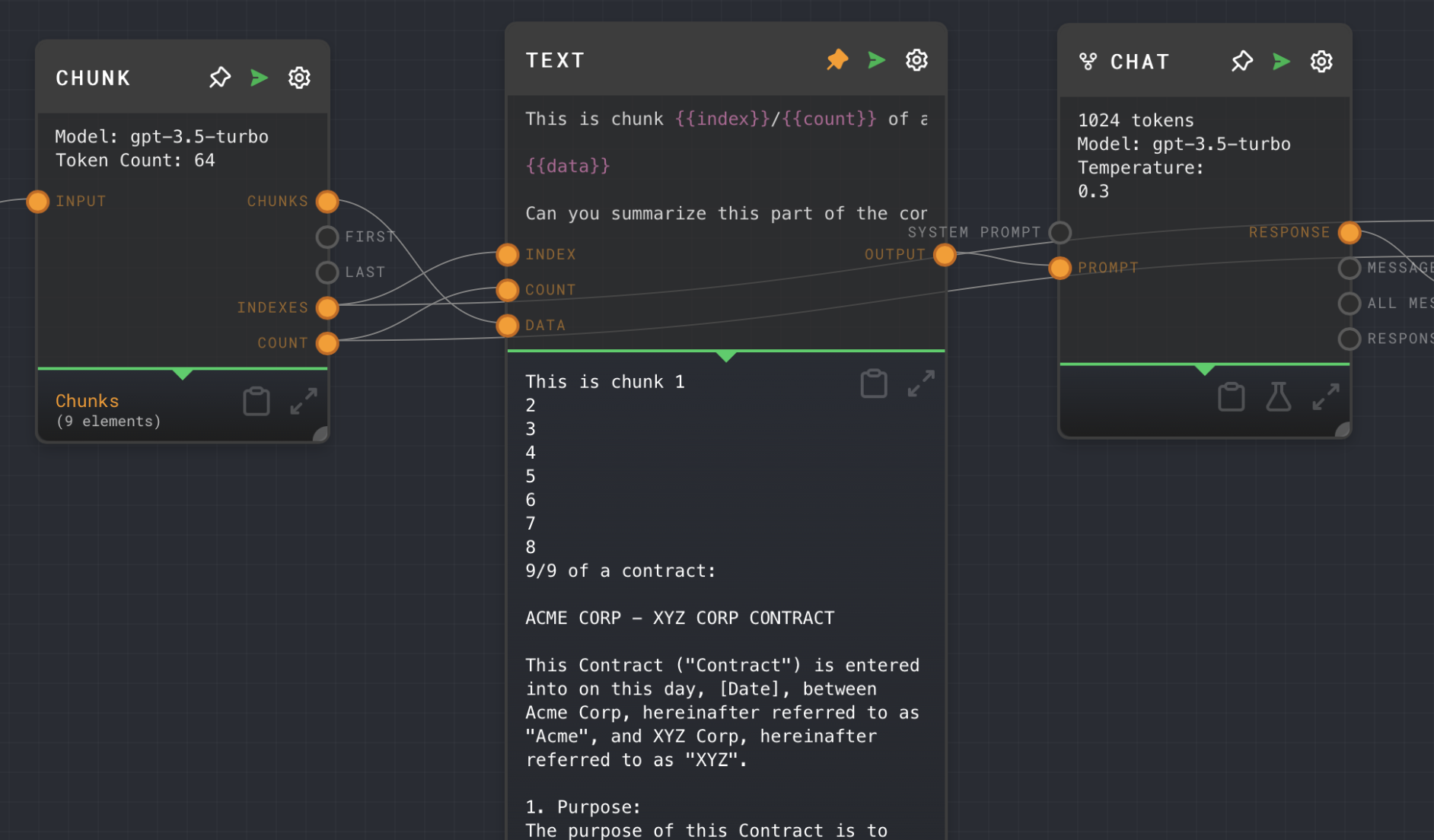
Now, turn off split mode, and run the graph. Notice that the output is a single string, with the chunk items all concatenated together ("This is chunk 1 2 3 4..." is happening because the index input is also an array). This is eventually how we will transform the array of summaries into a single answer.
Split mode can be configured with max and sequential. Max specifies the max iterations. Try setting it to 2, and notice that the remaining items get ignored. Sequential specifies whether to iterate over items one at a time, or in parallel.
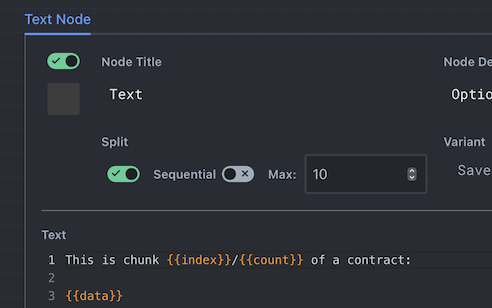
Now, notice that the Text Node has three inputs: index, count, and data. index is an array of sequential numbers, from 0 to N. data is the array of N text chunks. In split mode, these arrays are iterated over together, so that the i-th index is processed with the i-th text chunk. The count input is not an array, so it will stay constant throughout.
Warning: Try to keep input arrays to split nodes the same length. Otherwise, Rivet will go back to the start of any arrays that are shorter (which is unlikely to be the behavior you're looking for).
Combining
You can link nodes with split mode enabled to transform each item in an array. In the tutorial example, notice the split icon across the three nodes in the middle (Text, Chat, Text). The first Text Node inserts each chunk into a prompt template for summarization. Then, the Chat Node summarizes each chunk individually. Finally, the other Text Node adds some context for the summary.
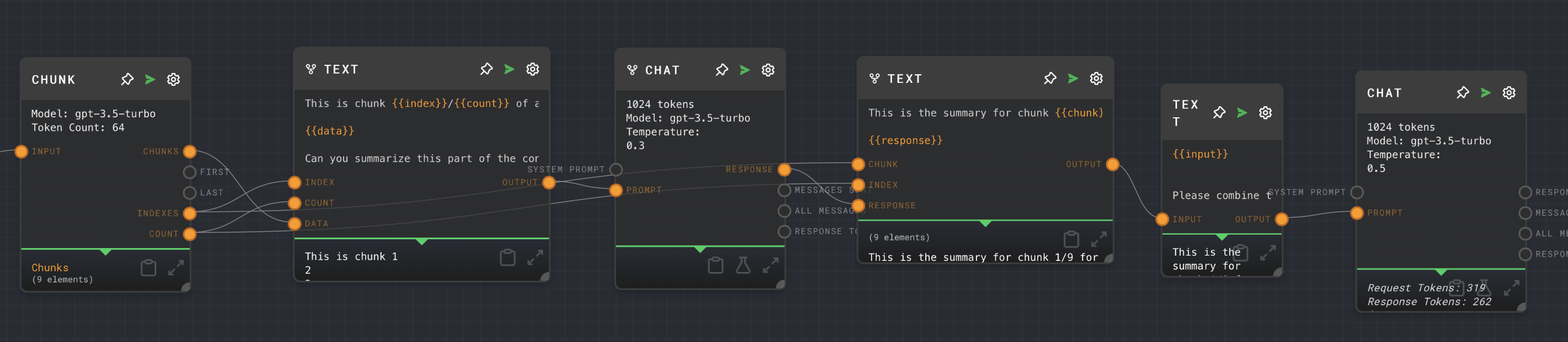
The resulting string array of summaries (and context about which chunk the summary comes from) is then combined into a Text Node with split mode turned off. By default, the string array input will get "coerced" into a string type by concatenating each item with a newline. If you want to combine them in a different way, consider something like the Join Node.