Chunk Node
Overview
The Chunk node is used to split a string into an array of strings based on a token count.
Chunking a string is useful to avoid hitting token count limited in LLMs. You can split a string into multiple chunks and then feed each chunk into a separate Chat node, then combine the outputs of the chat nodes back together to effectively answer questions about strings of text longer than the LLM can handle.
The Chunk node can also be used to truncate a string to a certain token count, from the beginning or the end, by using the first or last outputs.
If an overlap percentage is specified, then the chunks will overlap by the specified percentage (relative to the max token count). For example, if the max token count is 100 and the overlap is 50%, then the chunks will overlap by 50 tokens. This can be useful so that context is not lost between chunks, but it may result in more total chunks.
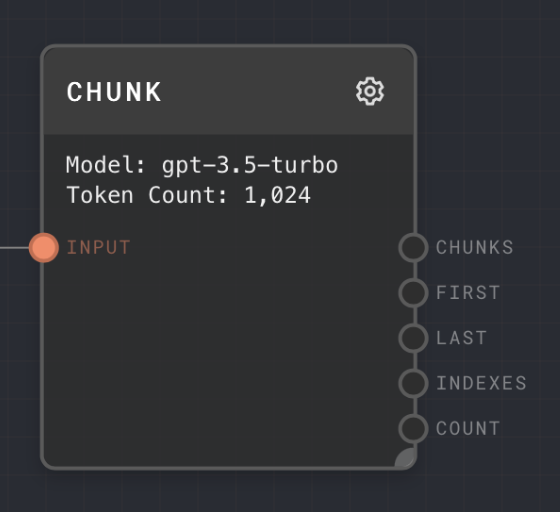
- Inputs
- Outputs
- Editor Settings
Inputs
| Title | Data Type | Description | Default Value | Notes |
|---|---|---|---|---|
| Input | string | The string that should be chunked. | (Required) | None |
Outputs
| Title | Data Type | Description | Notes |
|---|---|---|---|
| Chunks | string[] | The array of string chunks after splitting the string by the configured amount of tokens. | May be an array of length 1 if the string did not need to be split. |
| First | string | The first chunk in the chunks array. | Useful for truncating a string to a specified token count. |
| Last | string | The last chunk in the chunks array. | Useful for truncating a string from the start to a specified token count. |
| Indexes | number[] | A list of the indexes of the chunks. | Useful when filtering or zipping the chunks array, and other more complex tasks. |
| Count | number | The number of chunks in the chunks array. | Has many uses for more complex tasks. |
Editor Settings
| Setting | Description | Default Value | Use Input Toggle | Input Data Type |
|---|---|---|---|---|
| Model | The model to use for tokenizing. Different LLMs use different tokenizers. | gpt-3.5-turbo | Yes | string |
| Max Tokens | The maximum number of tokens in the chunk. | 1024 | Yes | number |
| Overlap | The amount of overlap (0-100% as 0-1) between chunks, as a factor of the max token count. | 0 | Yes | number |
Example 1: Chunk a string into multiple chunks
- Create a text node with some long data, such as lorem ipsum.
- Create a Chunk node and connect the text node to the input. Set the max tokens to something small like 100.
- Run the graph. Note how the output of the chunk node has split the text (visually as new lines) into multiple chunks.
Error Handling
The chunk node has no notable error handling behavior. If the input is not a string, then it will be coerced into a string.